广义线性模型
1、普通最小二乘法
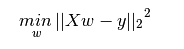
最小二乘的系数估计依赖于模型特征项的独立性。当特征项相关并且设计矩阵 的列近似的线性相关时,设计矩阵便接近于一个奇异矩阵,因此最小二乘估计对观测点中的随机误差变得高度敏感,产生大的方差。例如,当没有试验设计的收集数据时,可能会出现这种多重共线性(multicollinearity )的情况。
的列近似的线性相关时,设计矩阵便接近于一个奇异矩阵,因此最小二乘估计对观测点中的随机误差变得高度敏感,产生大的方差。例如,当没有试验设计的收集数据时,可能会出现这种多重共线性(multicollinearity )的情况。
2、岭回归、岭回归加交叉验证
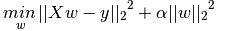
岭回归通过对系数的大小施加惩罚来解决普通最小二乘的问题。
3、Lasso
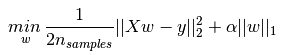
估计稀疏系数的线性模型 。它在一些情况下是有用的,因为它倾向于使用具有较少参数值的解决方案,有效地减少给定解决方案所依赖的变量的数量。
Lasso 类中的实现使用坐标下降作为算法来拟合系数。
由于 Lasso 回归生成稀疏模型,因此可以用于实现特征选择 。
4、Multi-task Lasso ( 多任务套索 )

MultiTaskLasso 是一个线性模型,它联合估计多个回归问题的稀疏系数:y 是一个二维数组,shape(n_samples,n_tasks)。约束是所选的特征对于所有的回归问题都是相同的,也称为 tasks ( 任务 )。
Lasso 估计产生分散的非零,而 MultiTaskLasso 的非零是全部。
拟合 time-series model ( 时间序列模型 ),强制任何活动的功能始终处于活动状态。
5、Elastic Net ( 弹性网 )、ElasticNetCV类
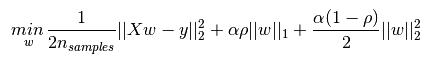
ElasticNet 是一种线性回归模型,以 L1 和 L2 训练为正规化。这种组合允许学习一个稀疏模型,其中很少的权重是非零的 。
当有多个相互关联的特征时,Elastic-net 是有用的。 Lasso 有可能随机选择其中之一,而 elastic-net 则很可能选择两者。
Lasso 和 Ridge 之间的一个实际的优势是允许 Elastic-Net 继承 Ridge 在一些旋转下的稳定性。
比较: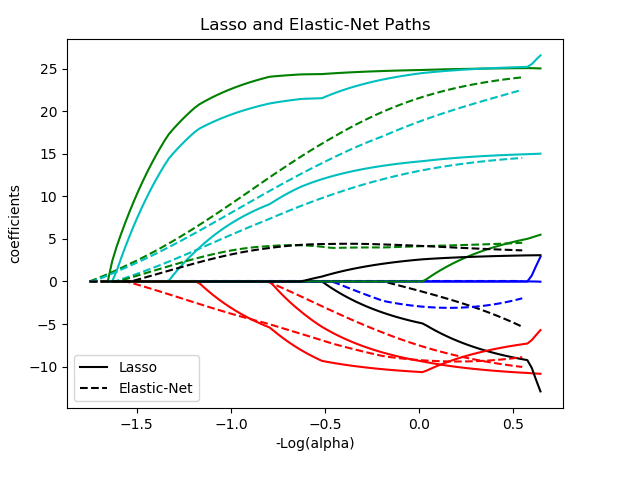
该程序设置l1_ratio=0.8,根据公式知道L1范数偏重,也就是此时在相同的a下,lasso的算出来的w(coe)会比elastic的大;当l1_ratio=0.5,两者的w接近相同。
6、LARS Lasso使用最小角度回归的拉索算法
与基于 coordinate_descent 的实现不同,这产生了精确的解,其作为其系数范数的函数是分段线性的。
7、Orthogonal Matching Pursuit (OMP) ( 正交匹配追踪(OMP) )
用于近似线性模型的拟合,并对非零系数(即 L 0 伪范数)施加约束。 作为 Least Angle Regression ( 最小角度回归 ) 的前向特征选择方法,正交匹配追踪可以用固定数量的非零元素逼近最优解矢量: 
OMP 基于一个贪心算法,每个步骤都包含与当前残差最相关的原子。它类似于更简单的匹配追求( MP )方法,但是在每次迭代中更好,使用在先前选择的词典元素的空间上的正交投影重新计算残差。
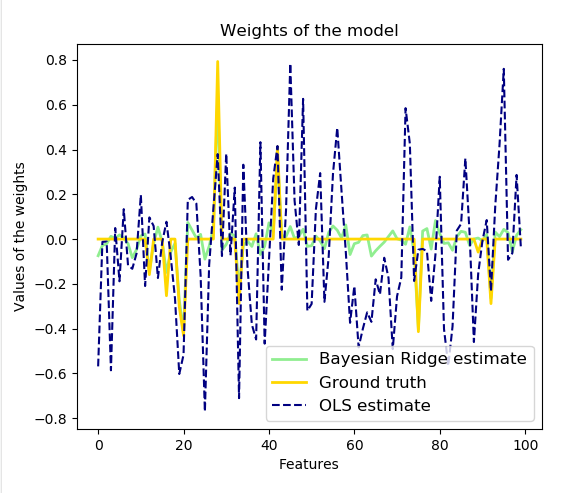
8、Bayesian Regression ( 贝叶斯回归 )
贝叶斯回归技术可以用于在估计过程中包括正则化参数:正则化参数不是硬的设置,而是调整到手头的数据。
这可以通过对模型的超参数引入 uninformative priors ( 不知情的先验 ) 来完成。Ridge Regression 中使用的 正则化等价于在精度为?的参数
正则化等价于在精度为?的参数  之前,在高斯下找到最大 a-postiori 解。而不是手动设置 lambda ,可以将其视为从数据估计的随机变量。
之前,在高斯下找到最大 a-postiori 解。而不是手动设置 lambda ,可以将其视为从数据估计的随机变量。
为了获得一个完全概率模型,输出y被假定为高斯分布在  周围:
周围:
Alpha 再次被视为从数据估计的随机变量。
贝叶斯回归的优点是:
- 它适应了 data at hand ( 手头的数据 ) 。
- 它可以用于在估计过程中包括正则化参数。
贝叶斯回归的缺点包括:
- 模型的推论可能是耗时的。
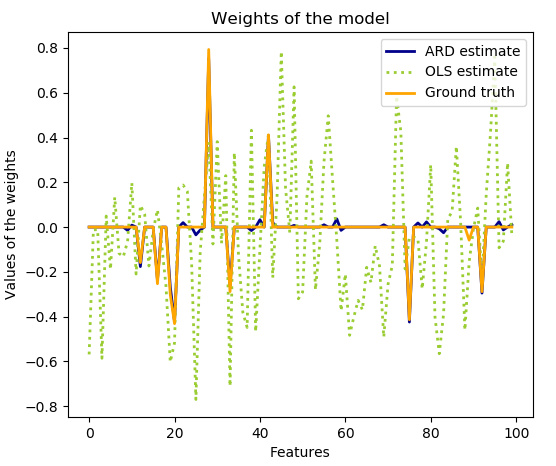
9、Automatic Relevance Determination - ARD ( 自动相关性测定 - ARD )
ARDRegression 与 Bayesian Ridge Regression ( 贝叶斯岭回归 ) 非常相似,但可以导致更稀疏的权重
ARDREgression 通过放弃高斯为球面的假设,构成了与 之前不同的先验。 相反,假定 上的分布是轴平行的椭圆高斯分布。 这意味着每个权重  从高斯分布绘制,以零为中心,精度为
从高斯分布绘制,以零为中心,精度为  :
:  与
与  。 与贝叶斯岭回归相反,每个 的坐标都有自己的标准偏差
。 与贝叶斯岭回归相反,每个 的坐标都有自己的标准偏差 。 先前的所有 被选择为由超参数
。 先前的所有 被选择为由超参数  和
和  给出的相同的伽马分布。
给出的相同的伽马分布。
10、Logistic regression ( 逻辑回归 )
Logistic regression ( 逻辑回归 ) ,尽管它的名字是回归,是一个用于分类的线性模型而不是用于回归。
可以从 LogisticRegression 类中访问 scikit-learn 中 logistic regression ( 逻辑回归 ) 的实现。该实现可以拟合 binary ( 二进制 ) ,One-vs- Rest ( 一对一休息 ) 或 multinomial logistic regression ( 多项逻辑回归 ) 与可选的 L2 或 L1 regularization ( 正则化 ) 。
作为优化问题,binary class L2 penalized logistic regression ( 二进制类 L2 惩罚逻辑回归 ) 使以下 cost function ( 成本函数 ) 最小化:

类似地, L1 regularized logistic regression ( L1 正则化逻辑回归 ) 解决了以下优化问题:

在 Logistic 回归类中实现的 solver ( 求解器 ) 是 “liblinear”, “newton-cg”, “lbfgs” and “sag”:
| Case | “sag” |
|---|---|
| Small dataset or L1 penalty | “liblinear” |
| Multinomial loss or large dataset | “lbfgs”, “sag” or “newton-cg” |
| Very Large dataset | “sag” |
11、Robustness regression: outliers and modeling errors ( 鲁棒性回归:异常值和建模误差 )
存在 presence of corrupt data ( 腐败数据 ) 的情况下拟合回归模型
一般来说,在高维度设置(大 n_features )中的 robust fitting ( 鲁棒拟合 ) 是非常困难的。这里的 robust models ( 健壮模型 ) 可能无法在这些设置中使用。
Scikit-learn 提供了 3 个 robust regression estimators ( 鲁棒的回归估计 ) :RANSAC , Theil Sen 和 HuberRegressor
- HuberRegressor 应该比 RANSAC 和 Theil Sen 更快,除非样本数量非常大,即 n_samples >> n_features 。这是因为 RANSAC 和 Theil Sen 适合较小的数据子集。然而, Theil Sen 和 RANSAC 都不太可能像 HuberRegressor 一样强大的默认参数。
- RANSAC 比 Theil Sen 快,随着样品数量的增加而增加
- RANSAC 将在y方向处理较大的异常值(最常见的情况)
- Theil Sen 将在 X 方向处理中等大小的异常值,但是这个属性将在高维度设置中消失。
- 如有疑问,请使用 RANSAC
12、Polynomial regression: extending linear models with basis functions ( 多项式回归:用基函数扩展线性模型 )
我们看到所得到的多项式回归与上面我们考虑过的线性模型相同(即模型在 w 中是线性的),并且可以通过相同的技术来解决。通过考虑使用这些基本功能构建的更高维度空间内的线性拟合,该模型具有适应更广泛范围的数据的灵活性。