常见的损失函数
通常机器学习每一个算法中都会有一个目标函数,算法的求解过程是通过对这个目标函数优化的过程。在分类或者回归问题中,通常使用损失函数(代价函数)作为其目标函数。损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越好,通常模型的性能越好。不同的算法使用的损失函数不一样。 损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。通常表示为如下:
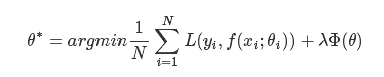
1、0-1损失函数和绝对值损失函数
0-1损失是指,预测值和目标值不相等为1,否则为0:
$$
L(Y,f(X))=\left{\begin{matrix}
1,& Y\neq f(X) & \
0,& Y=f(X) &
\end{matrix}\right.
$$
感知机就是用的这种损失函数。但是由于相等这个条件太过严格,因此我们可以放宽条件,即满足 |Y−f(X)|<T|Y−f(X)|<T 时认为相等。
$$
L(Y,f(X))=\left{\begin{matrix}
1,& |Y-f(X)|\geqslant T & \
0,& |Y-f(X)|<T &
\end{matrix}\right.
$$
绝对值损失函数为:
$$
L(Y,f(X))=|Y-f(x)|
$$
2、 平方损失函数
最小二乘法是线性回归的一种方法,它将回归的问题转化为了凸优化的问题。最小二乘法的基本原则是:最优拟合曲线应该使得所有点到回归直线的距离和最小。通常用欧几里得距离进行距离的度量。平方损失的损失函数为:
$$
L(Y|f(X))=\sum_{n} {(Y-f(X))^2}
$$
3、log对数损失函数
逻辑斯特回归的损失函数就是对数损失函数,在逻辑斯特回归的推导中,它假设样本服从伯努利分布(0-1)分布,然后求得满足该分布的似然函数,接着用对数求极值。逻辑斯特回归并没有求对数似然函数的最大值,而是把极大化当做一个思想,进而推导它的风险函数为最小化的负的似然函数。从损失函数的角度上,它就成为了log损失函数。 log损失函数的标准形式:
$$
L(Y,P(Y|X))=-logP(Y|X)
$$
4、Hinge损失函数
Hinge损失函数和SVM是息息相关的。在线性支持向量机中,最优化问题可以等价于
$$
min_{w,b}\sum_{i}^{N}(1-y_i(wx_i+b)) + \lambda||w^2||
$$
这个式子和如下的式子非常像:
$$
\frac{1}{m} \sum ^{m}_{i=1} {l(wx_i+by_i)} + ||w||^2
$$
其中l(wxi+byi)l(wxi+byi)就是hinge损失函数,后面相当于L2正则项。 Hinge函数的标准形式:
$$
L(y)=max(0,1-ty)
$$
y是预测值,在-1到+1之间,t为目标值(-1或+1)。其含义为y的值在-1和+1之间就可以了,并不鼓励|y|>1,即并不鼓励分类器过度自信,让某个正确分类的样本的距离分割线超过1并不会有任何奖励,从而使分类器可以更专注于整体的分类误差。
5、指数损失函数
AdaBoost就是一指数损失函数为损失函数的。 指数损失函数的标准形式:
$$
L(Y|f(X))=exp[-yf(X)]
$$
6、总图
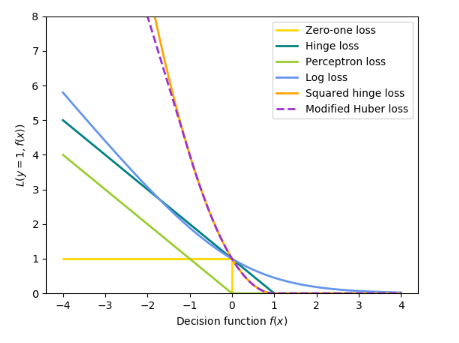
其中hinge loss是一次范式,squared hinged loss是二次范式